Securing a VMware Cloud Foundation (VCF) private cloud using VMware vDefend (leveraging the NSX and vDefend architecture) involves moving away from perimeter-only network security to a hypervisor-native Zero Trust model.
The step-by-step approach to implementing this security framework across your VCF infrastructure and applications is outlined below.
If you’ve been reading my recent posts on vPSO, you know I care about connecting theoretical security frameworks with real-world use in VMware Cloud Foundation (VCF). We’ve looked at how VMware vDefend serves as the main enforcer for NIST SP 800-53 Rev. 5, NIST SP 800-207 (Zero Trust), and NIST SP 800-82 Rev. 3 (OT/ICS).
Recently, NIST released an important document: NIST SP 800-239 (Initial Public Draft), titled “AI Data Center Security Analysis: A High-Performance Computing (HPC) Driven Approach.” If your organization is building AI infrastructure—whether for fine-tuning Large Language Models (LLMs), Retrieval-Augmented Generation (RAG) pipelines, or real-time inference—this publication is essential reading.
In this post, we’ll explain what NIST SP 800-239 is, why traditional data center security doesn’t work well in AI settings, and how to use VMware Avi Load Balancer (AVI) and VMware vDefend together to achieve the main objectives of this framework.
What is NIST SP 800-239 and Why Is It Different?
Traditional enterprise data centers are built around predictable application tiers (Web -> App -> DB).
AI data centers, however, inherit their architectural DNA from High-Performance Computing (HPC) environments. They feature:
Massive East-West Traffic: Unprecedented east-west bandwidth utilization across GPU clusters, high-speed interconnects, and distributed storage.
Complex Open-Source Software Stacks: Rapid adoption of fast-evolving tools like PyTorch, Ray, vLLM, Ollama, LangChain, and vector databases (e.g., Milvus, Pinecone, pgvector).
High-Value Assets: Highly sensitive intellectual property stored in model weights, training datasets, and prompt history.
Heavy API Exposure: Public or internal AI inference endpoints processing continuous streams of unstructured query payloads.
NIST SP 800-239 performs a comprehensive threat and gap analysis on these environments, identifying key risk areas such as Inference API exploits, prompt injection, compute exhaustion (DDoS on expensive GPU resources), data poisoning, model exfiltration, and lateral movement across high-speed fabrics.
To solve these challenges, we need a two-pronged defense strategy:
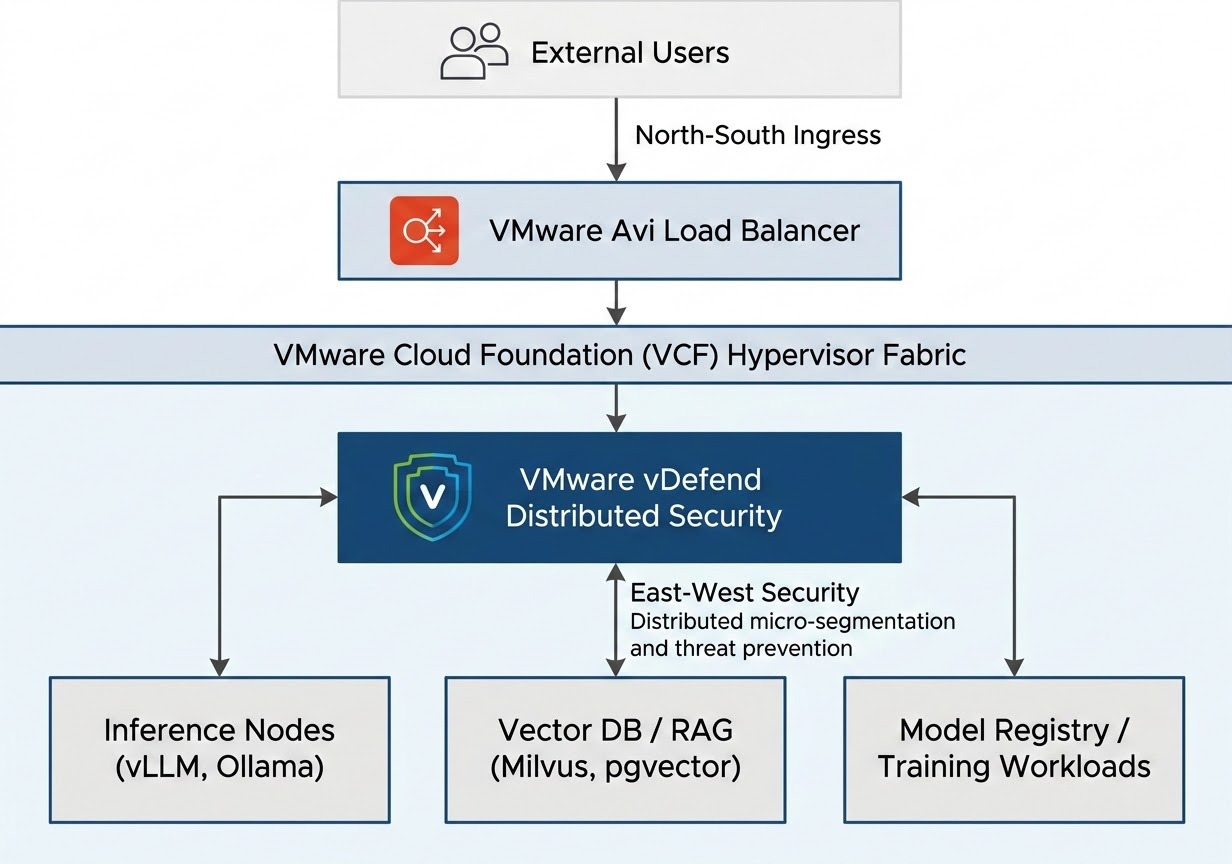
North-South Edge Protection & API Management: Guarding the entry points into AI inference and RAG pipelines (VMware Avi Load Balancer).
East-West Distributed Security & Micro-segmentation: Protecting internal workloads, model registries, vector databases, and GPU worker nodes (VMware vDefend).
Architectural Breakdown: Dividing North-South & East-West in AI Infrastructure
Deep Dive 1: Guarding the Front Door with VMware Avi Load Balancer
NIST SP 800-239 emphasizes that AI endpoints are prime targets for resource starvation and application-level exploits. Because AI inference queries consume significant GPU compute cycles, an unthrottled API endpoint can quickly lead to severe denial-of-service or astronomical cloud/compute bills.
Here is how VMware Avi Load Balancer delivers on NIST SP 800-239 North-South requirements:
1. Advanced Web Application Firewall (WAF) & API Security
OWASP for LLM Protection: Avi WAF inspects incoming HTTP/HTTPS payloads to detect malicious patterns, such as system prompt injections, SQL injections targeting vector store lookups, and Server-Side Request Forgery (SSRF) exploits designed to force inference servers to call unauthorized metadata services.
Schema Validation & API Sanity: Enforces strict API schemas on OpenAPI/Swagger specifications for AI inference endpoints, dropping malformed payloads before they hit python-based API engines.
2. GPU Protection via Intelligent Rate Limiting & DDoS Mitigation
Resource Exhaustion Defense: Standard HTTP rate-limiting isn’t enough when a single complex query can tie up multiple Tensor Core GPUs. Avi provides granular rate-limiting policies based on client IP, API token, or query parameters, protecting backend inference workers from compute-draining burst attacks.
L4-L7 Analytics: Real-time visual metrics display latency spikes, client IP distributions, and abnormal payload sizes, enabling rapid diagnosis of attack traffic versus legitimate spikes in LLM usage.
3. SSL/TLS Offloading and Inspection
High-performance SSL/TLS termination offloads crypto-processing from inference workloads, providing central inspection visibility into encrypted API streams prior to routing traffic to internal pods or VMs.
Deep Dive 2: Hardening the Internal AI Fabric with VMware vDefend
Once traffic crosses the perimeter, NIST SP 800-239 warns against assuming internal AI cluster components are safe. If an attacker compromises a web application server, they will attempt to move laterally to vector databases, extract proprietary fine-tuning data, or access model weights stored in model registries.
VMware vDefend provides kernel-level, Zero Trust lateral security natively within the hypervisor.
1. Zero Trust Micro-segmentation with Distributed Firewall (DFW)
Granular Isolation: vDefend DFW allows you to enforce strict firewall rules directly at the vNIC layer of every virtual machine or container host (VKS/vSphere Supervisor).
AI Pipeline Tiering: You can create logical security boundaries separating:
Inference Front-Ends to allowed to talk ONLY to Vector Databases on specific API ports.
Vector Databases to restricted from communicating directly with external egress gateways.
Model Registries / Storage to accessible ONLY by authenticated training or orchestration nodes.
2. Virtual Patching via Distributed IDPS (Turbo Mode)
Protecting Fragile AI Software Stacks: Open-source AI tools evolve rapidly, creating a wide attack surface of unpatched CVEs (e.g., vulnerabilities in Ray, PyTorch, or LangChain).
Hypervisor-Enforced DPI: vDefend Distributed Intrusion Detection and Prevention System (IDPS) inspects every packet passing through the vNIC. Using curated threat signatures, vDefend acts as a Virtual Patch, blocking exploit attempts at the hypervisor layer without requiring agent installations inside sensitive GPU guest operating systems.
Detecting Model Weight Exfiltration: Extracting a 70B parameter model weight file involves transferring gigabytes of binary data over the network. vDefend Security Intelligence maps all East-West traffic flows visually.
Threat Campaign Correlation: vDefend NDR correlates anomalous network behaviors—such as an inference node initiating a massive file transfer to an unauthorized staging server—alerting SOC teams before data exfiltration completes.
Mapping Matrix: NIST SP 800-239 Objectives to VMware Solutions
NIST SP 800-239 Security Goal
Threat / Challenge Identified
VMware Solution
Operational Capability
Inference Endpoint Security
Malicious prompt injection, malformed API payloads, SSRF targeting RAG sources.
VMware Avi Load Balancer
Avi WAF & API Security inspecting L7 traffic; schema enforcement for AI endpoints.
Compute Availability & DoS Mitigation
GPU compute exhaustion via malicious or excessive query flooding.
VMware Avi Load Balancer
L4-L7 Rate Limiting, DDoS protection, and traffic shaping tailored to heavy AI workloads.
East-West Containment
Unrestricted lateral movement between compromised web tiers and AI infrastructure.
VMware vDefend DFW
Kernel-level Zero Trust micro-segmentation isolating inference nodes, vector DBs, and model stores.
Software Stack Vulnerability Shielding
Zero-day exploits and CVEs in rapid-release open-source AI frameworks (PyTorch, Ray, etc.).
VMware vDefend IDPS
Virtual Patching using IDPS Turbo Mode to drop exploit packets before reaching vulnerable services.
Data & Model Exfiltration Defense
Unauthorized theft of model weights, training data, or prompt logs across the internal network.
VMware vDefend ATP & Security Intelligence
Flow visualization, anomalous traffic detection, and threat campaign correlation for massive data transfers.
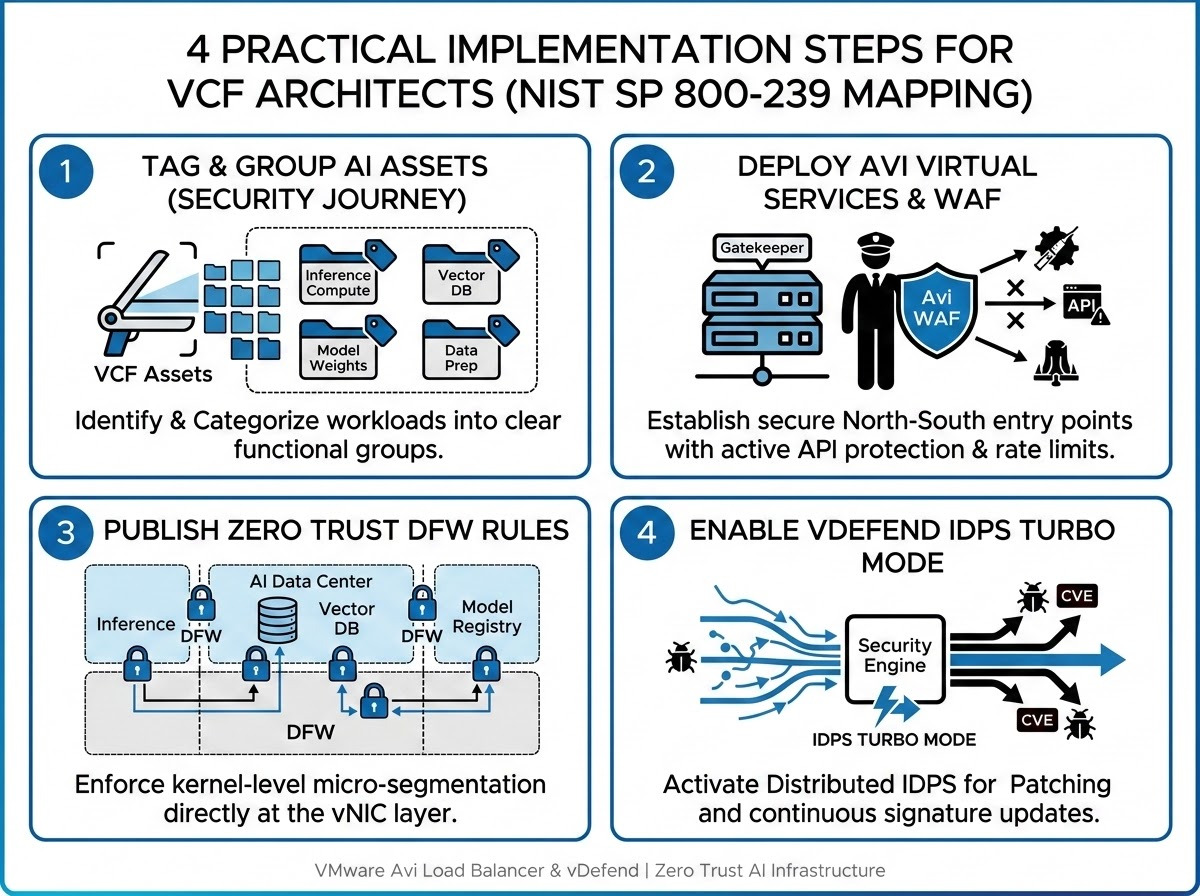
Practical Implementation Steps for VCF Architects
Ready to operationalize NIST SP 800-239 in your VCF environment? Follow this 4-step workflow:
Conclusion
NIST SP 800-239 makes one thing clear: AI infrastructure cannot be secured using legacy perimeter-only methods. The combination of high-value data assets, compute-intensive workloads, and complex software stacks demands a unified defense strategy.
By deploying VMware Avi Load Balancer at the ingress boundary and VMware vDefend natively within the VCF hypervisor fabric, you establish a resilient, end-to-end Zero Trust architecture capable of protecting your next-generation AI data centers.
Join the Conversation!
How is your organization securing AI workloads and RAG pipelines today? Have you started mapping NIST SP 800-239 into your architecture standards? Drop a comment below or reach out on LinkedIn—I’d love to hear how you’re tackling lateral security in the era of AI!
Don’t forget to subscribe tovPSOfor more deep dives into VMware Cloud Foundation, Zero Trust architecture, and cybersecurity compliance!
Securing the Private Cloud: Micro-Segmenting the VCF 9.1 Management Domain
As a Virtual Infrastructure (VI) Administrator, your primary mandate has historically been availability: keeping the lights on, the workloads running, and performance optimized. However, in the era of VMware Cloud Foundation (VCF) 9.1 and Frontier AI, security is no longer “someone else’s job.” When a security breach occurs, and an attacker moves laterally through a flat management network, the spotlight shines directly on the infrastructure layer. If the virtual network cards (vNICs) of your core management appliances are wide open, you—the VI Admin—become the liable party.
To prevent this, VCF 9.1 embraces a Zero-Trust architecture. Securing your private cloud begins on Day 1, starting with the heart of your infrastructure: the Management Domain.
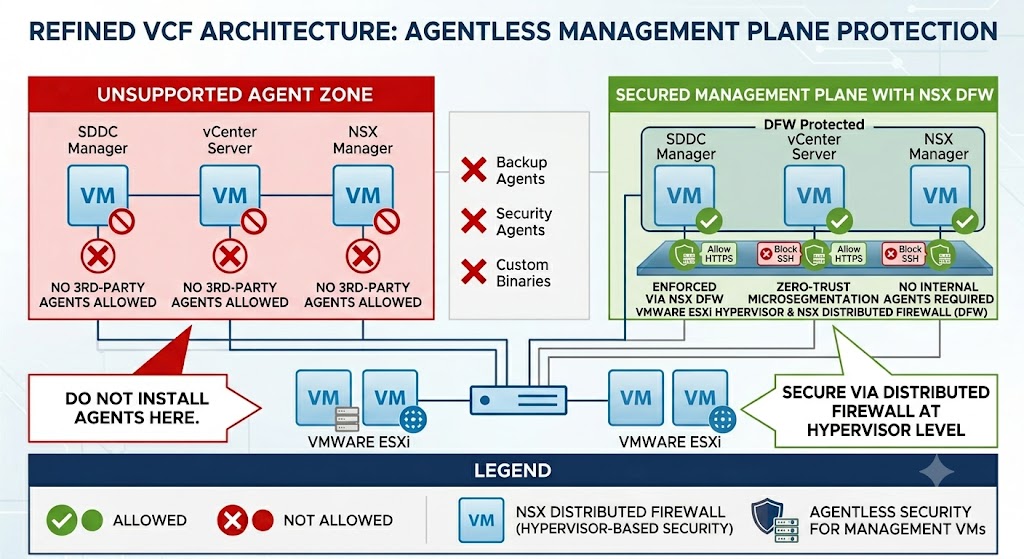
1. The Agentless Paradox: Securing the Untouchable Plane
Modern enterprise security tools love agents. Endpoint Detection and Response (EDR) agents, configuration management agents, and compliance scanners are often mandated across the estate.
However, no third-party agents are supported or allowed inside the VCF management plane appliances (SDDC Manager, vCenter Server, and NSX Managers).
Why? The VCF management plane is highly engineered, tightly integrated, and upgraded as a single, sovereign system. Installing third-party agents directly onto these Photon OS-based appliances risks:
Breaking critical API endpoints and inter-service communications.
Causing performance bottlenecks and kernel instability on critical control plane elements.
Blocking or corrupting lifecycle management (LCM) patching workflows during upgrades.
This is the Agentless Paradox: You must secure a control plane that you are not allowed to touch from the inside.
The solution? You don’t secure the operating system from within; you secure it at the hypervisor level.
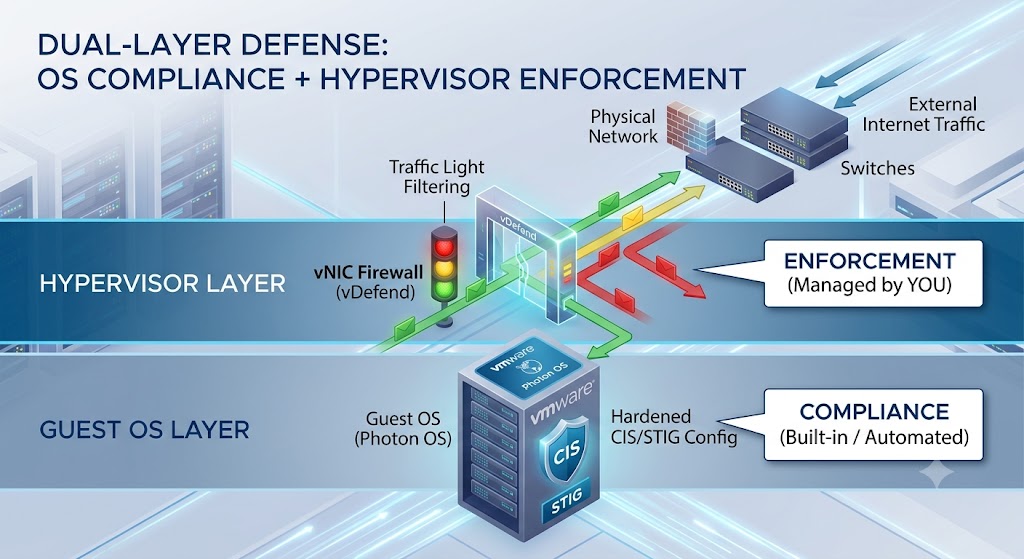
2. Dual-Layer Defense: OS Compliance + Hypervisor Enforcement
Securing the Management Domain requires a dual-layer approach. You must implement controls on both the guest Operating System (OS) and the hypervisor-managed virtual NIC (vNIC).
Guest OS Compliance (The Static Shield): Out of the box, VCF 9.1 appliances are hardened against CIS benchmarks and Federal STIG requirements. Standard settings like SSH timeouts, password complexity, and kernel-level hardening are built into the Photon OS appliances.
Hypervisor vNIC Enforcement (The Active Moat): This is where you come in. By leveraging the built-in VMware vDefend Distributed Firewall (DFW), you inspect and control every packet entering or leaving the vNIC of your management appliances before it even hits the guest OS network stack.
3. The “Traffic Light” Security Model: Red Means Stop
The concept behind hypervisor-level micro-segmentation is as simple as a traffic light:
🔴 Red Traffic (Default Stop): All communication is blocked by default. If a VM tries to talk to another VM laterally on the same management network, it is stopped dead in its tracks.
🟢 Green Traffic (Explicitly Allowed): Only verified, pre-approved infrastructure traffic is allowed to pass.
If a rule is not explicitly defined in your “Green” list, it is treated as a “Red” traffic light. This prevents a compromised utility VM or administrative jumpbox from being used to scan, exploit, and laterally infect vCenter or SDDC Manager.
4. Extracting the Blueprints: The VCF Configuration Workbook
Before writing firewall rules, you need the ground truth. This is found in the VCF Configuration Workbook (the deployment parameter spreadsheet completed during the planning phase and used by VCF Installer to orchestrate your Day 0 deployment).
Open your completed workbook and navigate to the following tabs to extract the IPs, hostnames, and subnets needed for your rules:
A. “Management Specs” Tab
Extract the exact IP addresses and Hostnames for your core management appliances:
SDDC Manager: Look for sddc-manager-ip and sddc-manager-fqdn.
vCenter Server: Locate vcenter-ip and vcenter-fqdn.
NSX Managers: Identify the NSX Manager Cluster Virtual IP (VIP) and the three individual controller IPs (nsx-mgr-01-ip, etc.).
B. “Hosts & Subnets” Tab
Extract your physical infrastructure IPs and network ranges:
ESXi Management VMkernel IPs: Note down the IP range or individual VMkernel (vmk0) IP addresses assigned to the physical ESXi hosts running your management workloads.
Management Subnet & Gateway: Note the CIDR block (e.g., 10.0.10.0/24) and gateway IP for the management network.
C. “External Services” Tab
Extract the corporate infrastructure servers designated during your VCF install:
Domain Name System (DNS): Primary and secondary DNS IP addresses.
Network Time Protocol (NTP): Your validated internal or external NTP servers.
Active Directory (AD) / Identity Providers: Domain Controller IPs used for LDAP/LDAPS configurations. In VCF 9.1, you can also natively integrate with the Symantec Identity Security Platform (IDSP) directly from VCF Operations to enable Multi-Factor Authentication (MFA), FIDO2/WebAuthn, and standardized VCF-level roles.
5. The VCF 9.1 Management Domain Firewall Rules Matrix
Below is the definitive “Traffic Light” rule matrix for your Management Domain. Implement this in your vDefend Distributed Firewall (DFW). In this table I am showing enforcing your VCF confrigruation at the hypervisor network with 9 simple rules. As you read this talbe think about, does my network team or security team own the Vitrual Distubited Switch?
Rule ID
Rule Name
Source Group
Destination Group
Services / Ports
Action
Description
MGMT-01
Allow NTP
VCF-Mgmt-Components
NTP-Servers
UDP 123
ALLOW
Crucial for time synchronization; out-of-sync clocks break SSO tokens and vSAN.
MGMT-02
Allow DNS
VCF-Mgmt-Components
DNS-Servers
UDP 53, TCP 53
ALLOW
FQDN resolution for all API endpoints, host management, and lookups.
Domain controller communications for user authentication and directory services.
MGMT-04
ESXi to vCenter
ESXi-Hosts
vCenter-Appliance
TCP 443 TCP/UDP 902
ALLOW
Core host management, agent heartbeat, and provisioning.
MGMT-05
vCenter to ESXi
vCenter-Appliance
ESXi-Hosts
TCP 443 TCP/UDP 902
ALLOW
vCenter dispatching tasks to ESXi, hosting consoles, and VM migrations.
MGMT-06
SDDC Manager Orchestration
SDDC-Manager
vCenter-ApplianceNSX-ManagersESXi-Hosts
TCP 443 (HTTPS) TCP 22 (SSH – temporary)
ALLOW
Day-2 operations, lifecycle management, and resource provisioning.
MGMT-07
Syslog / Monitoring
VCF-Mgmt-Components
Syslog-Servers
TCP/UDP 514 TCP 1514
ALLOW
Audit log forwarders to VCF Operations / external SIEM platforms.
MGMT-08
Restricted Admin UI
Admin-Jumpboxes
VCF-Mgmt-Components
TCP 443 (HTTPS) TCP 22 (SSH)
ALLOW
Encrypted administrative portal access. Never expose management interfaces to general user subnets.
MGMT-09
DEFAULT DROP (The Red Light)
VCF-Mgmt-Subnet
VCF-Mgmt-Subnet
ANY
🛑 DROP
The Default Block Rule. Prevents unauthorized lateral communication inside the management network.
6. Step-by-Step Implementation Guide
Follow this systematic process to safely configure and apply these rules in your VCF 9.1 environment without causing a self-inflicted outage.
Step 1: Create NSX Inventory Groups
Instead of writing rules using raw IP addresses, define reusable Groups inside NSX to keep your configuration clean and dynamic.
Log into your NSX Manager / vDefend Console.
Navigate to Inventory > Groups and click Add Group.
Create the following groups by adding IP addresses extracted from your VCF Workbook:
Grp-VCF-NTP: Add your NTP server IPs.
Grp-VCF-DNS: Add your DNS server IPs.
Grp-VCF-AD: Add your Domain Controller IPs.
Create dynamic groups based on VM tags or names:
Grp-SDDC-Manager: Criteria: VM Name equals sddc-manager.
Grp-vCenter: Criteria: VM Name contains vcenter.
Grp-NSX-Controllers: Criteria: VM Name contains nsx-manager.
Step 2: Define Custom Services (If Not Built-In)
Most core services (DNS, NTP, LDAPS, HTTPS) have built-in definitions in NSX. Double-check that they exist. If you use non-standard ports (e.g., custom Syslog ports), define them under Inventory > Services > Add Service.
Step 3: Author the “Green Light” Infrastructure Rules
Navigate to Security > Distributed Firewall.
Under the Category tab, select Infrastructure (for core network services like NTP, DNS, and AD) or Environment (for application/management relationships).
Click Add Policy and name it VCF-Management-Core-Policy.
Click Add Rule and construct the rules in the order shown in our Firewall Rules Matrix above:
Match the Source Group, Destination Group, and Service.
Under Action, select Allow.
Under Applied To, target only the specific management groups (this keeps the firewall engine efficient instead of evaluating every workload VM across your entire fabric).
Step 4: Implement the “Red Light” Default Drop
Before enabling a block rule, verify that all legitimate management traffic is passing without issues by checking the firewall hit counts and logging.
At the bottom of your Management Policy, add a final catch-all rule:
Source:Grp-VCF-Management-Subnet (the CIDR block for your management network).
Destination:Grp-VCF-Management-Subnet.
Service:Any.
Action:Drop.
Logging:Enabled (highly recommended so you can audit blocked traffic).
Click Publish to commit the changes to your ESXi host kernels.
Conclusion: Take Ownership of the Hypervisor Perimeter
In VCF 9.1, securing your private cloud is no longer about layering third-party, resource-heavy agents inside your VM OS. It is about establishing clear, hypervisor-enforced boundaries.
By pulling your structural parameters directly from your VCF Configuration Workbook, translating them into dynamic NSX Groups, and enforcing the Traffic Light Model, you protect your organization from catastrophic lateral network attacks.
Don’t wait for your next compliance audit or a security incident response team to highlight the gaps in your architecture. Hardening the management domain at the hypervisor level is your responsibility. Lock it down today!
Building the DMZ between you and critical private cloud infrastructure.
Written by Joe Tietz
In my previous post, we explored how the emergence of autonomous, offensive AI models like Claude Mythos Preview has compressed the vulnerability lifecycle from months to hours. We established that securing the VCF 9.1 Management Domain requires strict adherence to NIST 800-207 (Zero Trust) and utilizing the vDefend Distributed Firewall (DFW).
But micro-segmentation is only the first step. When facing an adversary that can autonomously generate infinite variations of a single exploit, a simple “allow/deny” port-based firewall isn’t enough. We need Holistic Security. We need VMware vDefend Advanced Threat Prevention (ATP).
Stopping the Onslaught of New Vulnerabilities
One of the most dangerous capabilities of modern AI threat actors is payload mutation. If an AI discovers a vulnerability in vCenter or SDDC Manager, it won’t just write one exploit; it will generate thousands of polymorphic variants designed to bypass traditional, hash-based antivirus and legacy firewalls.
This is where vDefend IDPS (Intrusion Detection and Prevention System) becomes the ultimate equalizer. By focusing on the core behavior and protocol anomalies of an attack rather than just static indicators of compromise (IoCs), vDefend IDPS enables true Virtual Patching.
When an AI-driven attack launches an onslaught of new vulnerabilities against your infrastructure, vDefend IDPS signatures act as an impenetrable shield. Because the IDPS engine sits directly at the vNIC of the workload via the hypervisor, it inspects every packet at line rate (supercharged by VCF 9.1’s Turbo Mode). It doesn’t matter if the AI mutated the payload wrapper 500 different ways; the IDPS catches the underlying exploit mechanism—whether it’s a command injection or a heap-overflow—and drops the traffic instantly. It buys your infrastructure team the critical time needed to test and deploy official patches without leaving the VCF Core exposed.
The Jump Box Story: A Fortress for the Keys to the Kingdom
To truly understand how holistic security operates in VCF 9.1, let’s look at the most critical access point in your environment: The Administrative Jump Box.
We’ve established a “Default Deny” posture around the VCF Management Plane. So, how do your authorized admins actually manage the environment? They use a dedicated jump box, but in the Mythos era, a jump box cannot just be a Windows Server with RDP enabled. It must be a fortress guarded by layered, intelligent security.
Here is an architecture to secure the workflow from end to end:
1. Getting on the Box: Elevated Credentials and MFA The first perimeter is access to the jump box itself. This is governed by strict identity access management. An administrator cannot simply log in with their daily-driver email account; they must use dedicated, elevated credentials (e.g., a VCF-Admin account). This access is explicitly gated by Multi-Factor Authentication (MFA). If you don’t have the token, you don’t get a session on the jump box. Period.
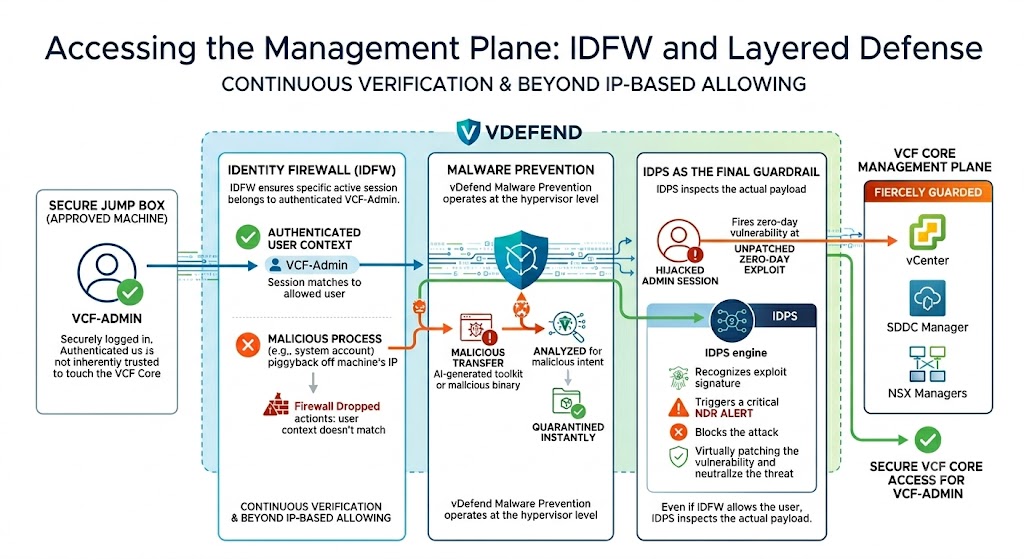
2. Accessing the Management Plane: IDFW and Layered Defense Once the admin is securely logged into the jump box, they are still not inherently trusted to touch the VCF Core. Access from the jump box to the Management Plane (vCenter, SDDC Manager, NSX Managers) is fiercely guarded by vDefend. It isn’t just about allowing an IP address; it’s about holistic, continuous verification:
Identity Firewall (IDFW): Even though the jump box is an approved machine, IDFW ensures that the specific active session attempting to connect to vCenter belongs to the authenticated VCF-Admin. If a malicious process running under a system account tries to piggyback off the machine’s IP, the firewall drops it because the user context doesn’t match.
Malware Prevention: As traffic flows from the jump box into the Management Plane, vDefend Malware Prevention operates at the hypervisor level. If a compromised jump box attempts to transfer an AI-generated toolkit or a malicious binary into the management environment, it is intercepted, analyzed for malicious intent, and quarantined instantly.
IDPS as the Final Guardrail: Let’s say an attacker manages to hijack an admin session and attempts a “living off the land” attack or fires an unpatched zero-day exploit straight from the jump box at vCenter. The traffic must pass through the vDefend IDPS engine. Even though the IDFW allows the user to talk to vCenter, IDPS inspects the actual payload. It recognizes the exploit signature, triggers a critical NDR alert, and that can feed our SEIM/SOAR to block the attack. Neutralizing the threat even when it originates from an approved, authenticated source.
Example: Jump Box IDPS Policy Table
To visualize how this looks in the vDefend console, here is an example of a strict IDPS rule set applied specifically to the Jump Box security group:
Defending the VCF 9.1 Core Part II: Holistic Security, The Jump Box, and Stopping the Vulnerability Onslaught
The Foundation: Securing Physical VLANs and OOB Networks
While vDefend secures the hypervisor and virtual management plane, a holistic security strategy must also account for the bare metal. The physical infrastructure powering VCF 9.1—specifically the Out-of-Band (OOB) networks (iDRAC, iLO, BMCs) and physical management VLANs (Top-of-Rack switches)—represents a critical attack surface.
If a threat actor bypasses the virtual layer and gains access to the OOB network, they can manipulate firmware, force hardware-level reboots, or completely wipe the ESXi hosts, rendering your virtual defenses moot.
To mitigate this physical risk, the Zero Trust mindset must extend to the physical switching fabric:
Strictly Isolated OOB: The OOB network should never be routable from general corporate networks or user VLANs. It must be heavily segmented at the physical core/distribution layers.
The Jump Box as the Sole Physical Gateway: Just as the Jump Box guards vCenter, it must be the only authorized pathway into the physical management and OOB VLANs.
Physical ACL Enforcement: Implement strict Access Control Lists (ACLs) on your physical routing layer. Ensure that only traffic originating from the heavily inspected Jump Box environment can reach the ToR switch management IPs and host BMCs.
By forcing physical management traffic through the secure jump box, we ensure that even hardware-level administration is subject to MFA, identity verification, and strict auditing.
Conclusion: The Holistic Imperative
In the era of machine-speed attacks, relying on isolated security products is a losing battle. You cannot bolt security on after the fact.
Holistic security means that Identity (IDFW), Access Control (DFW), Virtual Patching (IDPS), and Malware Prevention are all operating together, inherently baked into the VCF 9.1 hypervisor fabric. By utilizing vDefend , we ensure that even when adversaries unleash an onslaught of new vulnerabilities, our core infrastructure remains resilient, automated, and secure.
What layers of vDefend are you currently utilizing in your environment? Drop a comment below, and let’s keep the conversation going!
Executive Summary: The Speed of the Adversary Has Changed
In early April 2026, the cybersecurity landscape experienced a tectonic shift. Anthropic announced Project Glasswing and the restricted release of Claude Mythos Preview. This wasn’t just another language model; it was a demonstration of autonomous, AI-driven offensive cyber capabilities. We saw reports of models autonomously discovering zero-day vulnerabilities in mature codebases and—as highlighted by the recent Cloudflare incidents—chaining seemingly minor, low-severity bugs into devastating, multi-step exploits.
The human-driven vulnerability lifecycle (discovery, weaponization, patching) has been compressed from months to hours.
In my previous posts, we discussed how VMware Cloud Foundation (VCF) 9.1 introduces System Security Profiles and Turbo Mode to secure Agentic AI workflows. Today, we need to turn those same defensive weapons inward. How do we protect the “keys to the kingdom”—the VCF 9.1 Management Domain and critical Infrastructure Services—against an adversary that operates at machine speed? The answer lies in strict adherence to NIST frameworks and the aggressive application of vDefend Distributed Firewall (DFW) 1-2-3-4 methodology and Intrusion Detection/Prevention Systems (IDPS) for Virtual Patching.
The New Threat Landscape: Why Legacy Defenses Fail
The capabilities demonstrated by Mythos-class AI models render perimeter-only defenses entirely obsolete. Academic research is rapidly catching up to this reality. Recent evaluations demonstrate that Large Language Models (LLMs) are becoming highly proficient at solving complex Capture the Flag (CTF) offensive security challenges, mimicking real-world cyber threats at scale (Shao et al., 2024).
Furthermore, as organizations deploy advanced multi-agent systems, they introduce novel risks—such as systemic mis-coordination, collusion, and highly complex destabilizing dynamics—that we are only just beginning to understand (Hammond et al., 2025). Attackers are also bypassing traditional AI alignment and safety guardrails by employing multi-turn jailbreaks that distribute malicious intent across seemingly benign query sequences (Asl et al., 2025). Even the protocols designed to standardize AI tool usage, such as the Model Context Protocol (MCP), are creating vast new attack surfaces characterized by namespace typo-squatting, tool poisoning, and supply chain compromise (Hou et al., 2025).
When an AI can autonomously map a network, discover a zero-day in your DNS server, and execute a multi-stage payload in under 24 hours, traditional patching cycles are a death sentence.
Securing the VCF 9.1 Management Domain (NIST 800-207)
The VCF Management Domain houses vCenter Server, SDDC Manager, and the NSX Managers. If an attacker breaches this domain, they own the hypervisor fabric.
Applying Zero Trust (NIST SP 800-207): NIST 800-207 mandates that “all communication is secured regardless of network location.” We can no longer treat the Management VLAN as a trusted zone. By defining identity-based Security Groups (sg-), we can create a tight perimeter around these components.
Example: VCF Management Domain DFW Ruleset
Rule Name
Source (Group/Tag)
Destination (Group/Tag)
Service/Ports
Action
NIST 800-207 Alignment
Allow-Admin-Access
sg-admin-jumpboxes
sg-vcf-management
HTTPS (443), SSH (22)
ALLOW
Explicit, verified access for authorized admins only.
Allow-ESXi-to-vCenter
sg-esxi-hosts
sg-vcenter
UDP 902, HTTPS (443)
ALLOW
Least-privilege agent heartbeat and management traffic.
Allow-SDDC-Mgmt
sg-sddc-manager
sg-esxi-hosts, sg-vcenter
API, SSH (22)
ALLOW
Enables SDDC Manager lifecycle and automation workflows.
Mgmt-Lockdown
ANY
sg-vcf-management
ANY
DROP
Default Deny – Eliminates implicit trust to the core.
Micro-Segmentation via DFW: In VCF 9.1, we use the vDefend Distributed Firewall to enforce a “default deny” posture within the Management Domain, as demonstrated in the “Mgmt-Lockdown” rule above.
Identity-Based Security Groups: We move away from static IPs. By tagging management components, the DFW policy moves with the workload, ensuring that if a vCenter appliance is restored or migrated, its strict security perimeter remains intact.
Infrastructure Services—Active Directory (AD), DNS, NTP, and DHCP—are the nervous system of your data center. In Operational Technology (OT) and enterprise environments alike, these are prime targets for AI-driven reconnaissance and lateral movement.
Aligning with NIST SP 800-82 R3 (Boundary Protection): NIST 800-82 R3 emphasizes the need for strict network segmentation and boundary protection for critical systems.
DNS & NTP Isolation: These services should reside in a heavily restricted infrastructure tier. A compromised DNS server allows an attacker to manipulate traffic routing for the entire SDDC. We must enforce NIST 800-53 SC-7 (Boundary Protection) by using the DFW to restrict DNS traffic strictly to UDP/TCP 53, and only from designated internal subnets.
The “Any-Any” Trap: AI models look for overly permissive rules. Using vDefend Rule Analysts (RA) that is part of Security Intelligence we must map the baseline traffic of our AD and DNS servers and eliminate any shadowed or redundant “Allow Any” rules.
The Lifeline: Virtual Patching with vDefend IDPS
This is where VCF 9.1 truly shines against the Mythos-class threat. When a new vulnerability drops (or an AI discovers a zero-day that gets leaked), it takes time for vendors to release a patch, and even longer for infrastructure teams to schedule a maintenance window.
What is Virtual Patching? Virtual Patching utilizes the vDefend IDPS (Intrusion Detection/Prevention System) to inspect traffic for the specific exploit signatures of a vulnerability, blocking the attack before it reaches the unpatched application.
Command Injection during product migration leading to RCE.
Reject / Drop
SI-3 (Malicious Code Protection)
vCenter Server
CVE-2024-37079 (Sig 1140021)
DCERPC protocol Heap-overflow leading to Remote Code Execution.
Reject / Drop
SI-3, SC-7 (Boundary Protection)
ESXi Hosts
CVE-2025-22224 (Sig 1150999)
Hypervisor escape / Sandbox breakout from compromised VM.
Reject / Drop
SI-4 (Information System Monitoring)
Web UI / Agents
CVE-2026-39365 (Sig 4105305)
Path Traversal attacks in Vite Servers used by AI frontends.
Reject / Drop
SI-10 (Information Input Validation)
How it works in VCF 9.1:
Hypervisor-Level Enforcement: The IDPS engine sits directly at the vNIC of the VM. Traffic doesn’t need to be hairpin-routed to a physical appliance.
Turbo Mode Acceleration: With VCF 9.1’s Turbo Mode utilizing SCRX acceleration, we can run deep packet inspection (DPI) and IDPS at up to 9 Gbps per host. This means we can aggressively inspect traffic hitting our DNS, AD, and vCenter servers without crushing performance.
Dynamic Threat Intelligence: VMware’s Threat Intelligence cloud pushes updated signatures continuously, enabling zero-day defense before official vendor patches can be fully tested and deployed.
NIST 800-53 R5 Alignment:
SI-3 (Malicious Code Protection): IDPS drops payloads attempting to execute remote code on management appliances (like the vCenter DCERPC exploit).
SI-4 (Information System Monitoring): The IDPS feeds alerts directly into the vDefend NDR console, providing your SOC with immediate visibility if an AI-driven attack is attempting to probe your infrastructure services.
Conclusion: Matching Machine Speed
The release of models like Claude Mythos Preview through Project Glasswing signifies a permanent escalation in cyber warfare. The attacker is no longer a human manually typing commands; it is an autonomous system iterating through exploit chains at machine speed.
To survive, our defenses must also operate at the infrastructure level. By combining the strict Zero Trust micro-segmentation of the vDefend DFW with the high-performance Virtual Patching capabilities of the VCF 9.1 IDPS, we transition from a reactive patching cycle to a proactive, defensible architecture. In the age of AI threats, the network itself must become the immune system.
What’s Your Defense Strategy?
Are you ready to turn your network into an immune system? I’d love to hear how your teams are adapting to these AI-driven threats.
Join the conversation: Drop a comment below on your experience with vDefend IDPS or your zero-trust journey. What challenges are you facing with virtual patching?
Need a customized blueprint? Reach out to VMware by Broadcom Account Team to discuss how VMware PSO can help you design and deploy a defensible VCF 9.1 architecture.
Stay ahead of the curve:Subscribe now so you never miss a deep dive into VMware security, NIST compliance, and my ongoing vDefend DFW journey!
References
Asl, J. R., Narula, S., Ghasemigol, M., Blanco, E., & Takabi, D. (2025). NEXUS: Network Exploration for eXploiting Unsafe Sequences in Multi-Turn LLM Jailbreaks. arXiv. https://doi.org/10.48550/arxiv.2510.03417 Cited by: 6
Hou, X., Zhao, Y., Wang, S., & Wang, H. (2025). Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions. arXiv. https://doi.org/10.48550/arxiv.2503.23278 Cited by: 540
Shao, M., Jancheska, S., Udeshi, M., et al. (2024). NYU CTF Bench: A Scalable Open-Source Benchmark Dataset for Evaluating LLMs in Offensive Security. arXiv. https://doi.org/10.48550/arxiv.2406.05590 Cited by: 30
Working with friends at Google and Notebook LLM, I created nice little infographic with a podcast. My friends, are not security experts and need learn to say “AVI” correctly. But in the end they did great job, relating security story to the real world. Securing VCF with the Power vDefend and Avi.
Story starts current time as walks through vDefend DFW Security Journey.
The next day started the planing session in my favorite meeting rooms.
We return to the Network Operation Center to review our work at the end of the week
Kudos to Gemini for all the help with this comic, using AI to create this was interesting as show cases limitations of different AI tools. I believe I could pay for another tool but I wanted to test the limits with in Gemini today.
The author wishes to acknowledge the valuable contributions and review provided by Leo DeCoteau, which greatly improved the quality and accuracy of this document.
Section 1: Foundational Frameworks for Secure OT/IT Convergence
The contemporary industrial enterprise faces a fundamental tension between the operational necessity of digital transformation and the security imperative of protecting critical infrastructure. The historical model of complete physical isolation, or “air-gapping,” of Operational Technology (OT) environments is no longer tenable in an era that demands data-driven decision-making, remote monitoring, and integrated business logistics. Consequently, the architectural paradigm has shifted from absolute isolation to controlled, secured, and continuously monitored convergence. This blog post outlines a resilient architecture for OT application delivery that is founded upon three pillars of modern industrial cybersecurity: the structural segmentation of the Purdue Enterprise Reference Architecture (PERA), the prescriptive security controls of the National Institute of Standards and Technology (NIST) Special Publication (SP) 800-82 Revision 3, and the operational philosophy of a Zero Trust Architecture (ZTA). The convergence of these frameworks establishes a defensible boundary at the nexus of Information Technology (IT) and OT, enabling secure data exchange while mitigating the significant risks posed by an interconnected landscape.
1.1 The Purdue Enterprise Reference Architecture (PERA): A Model for Logical Segmentation
The Purdue Model serves as the foundational blueprint for segmenting industrial networks. It organizes Industrial Control Systems (ICS) and enterprise networks into a logical hierarchy of distinct layers, or levels, thereby separating the real-time, high-availability OT functions from the general-purpose, transaction-oriented IT systems. This hierarchical structure is not merely a network topology diagram; it is a security framework that dictates communication flows and establishes trust boundaries. A thorough understanding of each level is essential for implementing effective security controls.
Level 0 (Physical Process): This is the foundation of the industrial process, comprising the physical devices that interact directly with the physical world. Assets at this level include sensors (e.g., temperature, pressure, flow), actuators, motors, and valves. The primary security concern at this level is physical security and ensuring the integrity of the signals being sent and received.
Level 1 (Intelligent Devices): This level consists of the intelligent devices that directly monitor and manage the physical processes at Level 0. These include Programmable Logic Controllers (PLCs), Remote Terminal Units (RTUs), and Intelligent Electronic Devices (IEDs). These devices interpret data from sensors and execute commands to actuators, often operating under strict real-time constraints. They are vulnerable due to their often-limited computing power and legacy operating systems.1
Level 2 (Area Supervisory Control): This level involves the systems used by human operators to supervise and control specific sections or areas of the facility. Key components include Human-Machine Interfaces (HMIs) and Supervisory Control and Data Acquisition (SCADA) software. These systems aggregate data from Level 1 devices, manage alarms, and allow for real-time adjustments to the process.1
Level 3 (Site Operations): At the top of the OT zone, Level 3 contains systems that manage site-wide production workflows and operations. This includes assets such as data historians, alarm servers, and plant-level analytics platforms. This level represents the first line of defense between the process control environment and the enterprise IT network.
Level 4 (Business Logistics): Residing in the IT zone, Level 4 houses the business logistics systems that orchestrate manufacturing operations. These include Enterprise Resource Planning (ERP), Customer Relationship Management (CRM), and other systems crucial for business planning. Data from the OT environment is integrated here to inform high-level decision-making.
Level 5 (Enterprise Network): The highest level of the model, Level 5, encompasses the corporate IT network. This includes standard enterprise services such as email, file storage, internet access, and general user workstations. From a security perspective, this level is considered the most untrusted and is the primary source of external threats targeting the industrial environment.
The fundamental security principle of the Purdue Model is the enforcement of hierarchical data flow. Communication should be restricted to adjacent levels only. For instance, a system in the Enterprise Zone (Level 4/5) should never be permitted to communicate directly with a control system in Level 2. All traffic must be mediated and inspected as it traverses the levels, ensuring that a compromise in the less-trusted IT environment cannot directly impact the highly sensitive OT environment.
Table 1.1: Purdue Model Level Definitions and Security Characteristics
Level
Name
Typical Assets
Communication Flow
Primary Security Concern
5
Enterprise Network
Corporate Servers, Email, Internet Access, User Workstations
Unauthorized Access, Lateral Movement from IT to OT
3
Site Operations
Data Historians, Alarm Servers, Site MES
To/From Level 3.5 and Level 2
Loss of View, Manipulation of Site-Wide Production Data
2
Area Supervisory Control
HMIs, SCADA Systems, Engineering Workstations
To/From Level 3 and Level 1
Loss of Control, Manipulation of Local Process View
1
Intelligent Devices
PLCs, RTUs, IEDs
To/From Level 2 and Level 0
Manipulation of Control Logic, Denial of Control
0
Physical Process
Sensors, Actuators, Motors, Valves
Physical I/O to/from Level 1
Physical Tampering, Signal Integrity
1.2 The Industrial DMZ (Level 3.5): The Nexus of Secure Convergence
The Industrial Demilitarized Zone (iDMZ), classified as Level 3.5, is a modern, security-driven addition to the Purdue Model. It is a buffer network zone that sits between the IT and OT environments, specifically between Level 4 and Level 3. The primary purpose of the iDMZ is not to host operational applications but to serve as a dedicated security zone that enforces data security policies and prevents direct communication paths between the enterprise and industrial networks.
The iDMZ is the architectural embodiment of the shift from air-gapped isolation to secure convergence. It acts as a critical chokepoint where all traffic attempting to cross the IT/OT boundary can be terminated, inspected, authenticated, and controlled. This prevents the lateral movement of threats from the IT network into the OT environment while still allowing for the necessary, authorized flow of data, such as production data from a Level 3 historian to a Level 4 ERP system. By forcing traffic through brokered services within the iDMZ, such as proxies and application gateways, organizations can ensure that no session from the untrusted IT zone ever directly reaches the trusted OT zone.
1.3 Core Tenets of NIST SP 800-82 Revision 3: The Authoritative Guide for OT Security
NIST SP 800-82 Revision 3, “Guide to Operational Technology (OT) Security,” is the authoritative U.S. government standard for securing industrial systems. Its latest revision significantly expands its scope from a narrow focus on ICS to the broader category of OT, encompassing a wide range of cyber-physical systems, including building automation and transportation systems.
The standard provides comprehensive guidance on OT risk management, advocating for a defense-in-depth architecture and the implementation of security controls that are specifically tailored to the unique performance, reliability, and safety requirements of OT environments. A central recommendation of NIST 800-82 R3 is the implementation of robust network segmentation. The guide explicitly advises separating OT networks from IT networks and using a DMZ as a key enforcement boundary to monitor, log, and filter all inter-network traffic. This recommendation directly validates the use of the Purdue Model as a foundational architectural pattern.
Furthermore, NIST 800-82 R3 introduces the concept of an “OT overlay” for the security controls cataloged in NIST SP 800-53. This overlay provides tailored baselines of security controls for low-, moderate-, and high-impact OT systems, offering a concrete framework for selecting and implementing the specific safeguards needed to protect critical infrastructure. This blog post will leverage the OT overlay as the basis for mapping specific AVI platform capabilities to NIST-recommended controls.
1.4 Applying Zero Trust Principles to the iDMZ
The Zero Trust Architecture (ZTA), as defined in NIST SP 800-207, is a cybersecurity model founded on the principle of “never trust, always verify”. It assumes that a breach is inevitable or has already occurred, and therefore, no user or device can be implicitly trusted based on its network location, whether inside or outside the perimeter. This philosophy is perfectly suited for governing the iDMZ, which serves as the boundary between the untrusted IT world and the trusted OT world.
The iDMZ is the logical and ideal location to implement the core components of a ZTA. According to NIST SP 800-207, all communication must be secured regardless of network location, and access to resources must be granted on a per-session basis, enforcing the principle of least privilege. This means every request from an IT system to access an OT-related application service exposed in the iDMZ must be independently authenticated and authorized. The iDMZ becomes the Zero Trust boundary, and the application delivery platform within it acts as the Policy Enforcement Point (PEP), making access decisions based on dynamic, context-aware policies. This approach moves beyond static firewall rules and enables a more granular, identity-aware security posture that is essential for protecting high-value OT assets.
The synthesis of these foundational frameworks provides the intellectual underpinning for a robust and defensible architecture. The Purdue Model supplies the structural blueprint for segmentation, defining where the IT/OT boundary exists. NIST SP 800-82 R3 provides the prescriptive security guidance, defining what specific controls and architectural patterns, such as the DMZ, are required at that boundary. Finally, the Zero Trust model provides the operational philosophy, defining how those controls should function: dynamically, on a per-request basis, and with no implicit trust.
Section 2: VMware AVI Platform Architecture and Capabilities
The VMware AVI Load Balancer (formerly Avi Networks) is an application delivery platform built on a software-defined, scale-out architecture that fundamentally separates the control plane from the data plane. This architectural design is not merely a technical detail; it is a key enabler for implementing the segmented, secure architecture required by the Purdue Model and NIST 800-82 R3. Unlike monolithic hardware appliances, AVI’s decoupled nature allows for strategic placement of its components in alignment with security zone principles, providing flexibility, scalability, and centralized control without compromising the integrity of the IT/OT boundary.
2.1 Decoupled Control and Data Planes: The Foundation of Flexibility
The AVI platform is composed of two primary components that operate independently but in concert.
The Avi Controller Cluster (Control Plane): The Controller is the centralized “brain” of the AVI platform. It serves as the single point of management, policy configuration, and analytics aggregation for the entire system. For high availability, the Controller is deployed as a three-node, active-active cluster, which ensures that the management plane remains operational even in the event of a single or dual node failure. A virtual IP (VIP) address is assigned to the cluster, providing a single, resilient endpoint for all administrative and API interactions. The Controller houses the policy engine and exposes a 100% REST API, making it fully automatable and integratable with CI/CD pipelines and orchestration tools.
The Avi Service Engines (Data Plane): The Service Engines (SEs) constitute the distributed data plane. These are lightweight, high-performance load balancers that handle all application traffic. SEs are deployed as virtual machines or containers and are placed proximate to the applications they are servicing. They receive their configuration from the Controller and stream a rich set of near-real-time telemetry and logs back to it. This architecture allows the data plane to be elastically scaled out or in based on application demand, without requiring manual intervention.
This separation of planes is the cornerstone of the platform’s architectural advantage. It allows the control plane (the Controller cluster) to be deployed and managed within the IT zone, where administrative access is appropriate, while the data plane (the SEs) can be deployed in a secure enforcement zone like the iDMZ. This alignment with the Purdue Model’s segmentation goals is difficult to achieve with traditional, monolithic load-balancing appliances, which would require extending management access directly into the secure zone, thereby creating an undesirable attack vector.
2.2 High Availability and Resiliency Models
Ensuring continuous availability is a paramount concern in OT environments. The AVI platform provides robust high availability (HA) at both the control and data plane levels.
Controller Cluster HA: The three-node Controller cluster operates in an active-active model, with a leader elected to handle certain tasks but with all nodes capable of serving API requests. If the leader node fails, a new leader is elected from the remaining nodes, ensuring the management plane remains available. A two-node failure will result in a loss of quorum, hence preventing any new configurations on the control plane. If all three nodes of the control plane are offline, the data plane continues to function in a headless state. Application traffic continues to flow through the data plane; however, new configurations are only possible once the control plane is restored.
Service Engine HA Modes: The SEs, which handle the live application traffic, can be configured in several HA modes to ensure data plane resiliency. The choice of mode depends on the specific requirements for failover time, resource utilization, and scalability.
Legacy HA (Active/Standby): This is a traditional HA model where two SEs are paired. One SE is active and handles all traffic for a given virtual service, while the other remains in a standby state. Upon failure of the active SE, the virtual service fails over to the standby SE. This model is simple but does not permit active load sharing for a given virtual service or scaling beyond two SEs.
Elastic HA N+M Mode: This is the default and most commonly recommended mode. In an N+M configuration, ‘N’ SEs are actively handling traffic, while ‘M’ additional SEs are deployed as a buffer. If one of the ‘N’ active SEs fails, the Controller automatically moves its virtual services to one of the ‘M’ buffer SEs. This provides a balance between resource efficiency and failover capacity.
Elastic HA Active/Active Mode: In this high-performance model, a single virtual service is scaled out across multiple active SEs simultaneously. If one SE fails, it only results in a partial degradation of capacity for the virtual service, as the remaining SEs continue to handle their share of the traffic. This mode offers the fastest failover and is ideal for mission-critical applications where even a brief interruption is unacceptable.
2.3 Core Communication Paths and Network Requirements
A secure and functional deployment of the AVI platform requires specific communication paths to be allowed through network firewalls. Each path serves a distinct purpose and must be explicitly permitted.
Controller-to-SE Communication: The Controller communicates with the SEs over a secure channel to push configuration, check health status (heartbeats), and receive metrics and logs. This requires allowing SSH (TCP/22) and a secure control channel (TCP/8443) from the SEs management IPs to the Controller IPs.
Intra-Controller Cluster Communication: The nodes within the Controller cluster must communicate with each other to maintain quorum, elect a cluster leader, replicate configuration, and synchronize state. This requires allowing traffic between the Controller nodes on TCP ports 22, 443 and 8443.
SE-to-SE Communication: For Elastic HA modes, the SEs within a Service Engine Group send health monitoring heartbeats to each other over their data interfaces. This requires allowing traffic between the SE data IPs using TCP Ports 9001 and 4001.
Administrative Access: Human administrators and automation systems access the platform’s UI and API via the Controller Cluster VIP. This requires allowing HTTPS (TCP/443) access from authorized administrative networks to the Controller Cluster VIP.
Table 2.1: Required Network Communication Ports for AVI Platform
Section 3: Integrated Design: Deploying VMware AVI in a Purdue-Aligned Architecture
This section presents the definitive architectural blueprint for deploying the VMware AVI platform in a manner that is strictly aligned with the Purdue Model and fortified by the principles of NIST 800-82 R3. The design leverages AVI’s decoupled architecture to strategically place components in their appropriate security zones, establishing a robust and inspectable boundary between the IT and OT environments.
3.1 Strategic Component Placement
The placement of AVI components is one of the most critical architectural decisions and directly reflects the security principles of the Purdue Model.
Avi Controller Cluster in the Enterprise Zone (Level 4): The three-node Avi Controller cluster will be deployed on the IT Management Network, which resides within the Purdue Model’s Level 4. This placement is deliberate and offers several key advantages. It allows network administrators, security teams, and automation tools residing within the corporate network to access the central management and analytics plane of the AVI platform without requiring privileged access that crosses into more secure zones. Centralizing control in the appropriate administrative domain simplifies management and aligns with the principle of least privilege, as IT personnel do not need direct network access to the iDMZ or OT zones to perform their duties.
Avi Service Engines in the Industrial DMZ (Level 3.5): In accordance with the primary design constraint, the Avi Service Engines (SEs) will be deployed within the Industrial DMZ at Level 3.5. This placement positions the SEs as security gateways that proxy all application traffic flowing between the IT and OT networks. The SEs become the primary policy enforcement point, terminating connections from the less-trusted IT side, inspecting the traffic for threats, and then initiating new, clean connections to the application servers on the more-trusted OT side. This “proxy-in-the-middle” architecture is fundamental to preventing the direct propagation of threats and enforcing granular security policies at the IT/OT boundary.
3.2 Logical Network Topology and Traffic Flows
To support the strategic component placement and enforce strict segmentation, a specific logical network topology is required. This topology utilizes multiple network segments (which can be implemented as VLANs) to isolate different types of traffic and enforce the principle of least privilege at the network layer.
Network Segmentation Design:
IT Management Network (Level 4): A dedicated network segment within the corporate data center for the management interfaces of the three Avi Controller nodes and the Controller Cluster VIP.
iDMZ Management Network (Level 3.5): A dedicated network segment within the iDMZ for the management interfaces of the Avi Service Engines. The firewall policy between Level 4 and Level 3.5 must explicitly allow communication from the SE management IPs to the Controller IPs on TCP ports 22 and 8443.
iDMZ Front-End “VIP” Network (Level 3.5): This segment hosts the Virtual IPs (VIPs) for the applications being protected. It is the destination network for clients in the IT zone (Level 4/5) who are accessing OT applications. The firewall must allow application-specific traffic (e.g., TCP/443 for HTTPS) from authorized client networks to the VIPs on this segment.
iDMZ Back-End Data Network (Level 3.5): This segment is used for the SEs’ data interfaces that communicate with the back-end application servers in Level 3. The firewall policy between Level 3.5 and Level 3 must be highly restrictive, allowing traffic only from the SEs’ back-end interface IPs to the specific application servers on their required ports.
This multi-network design for the SEs within the iDMZ constitutes a form of microsegmentation within the boundary itself. It ensures that an attacker who compromises a system in the IT zone can only reach the front-end VIPs. They have no direct network path to the back-end OT application servers. To reach those servers, they would need to successfully exploit a vulnerability in the application presented on the VIP and then pivot through the AVI SE’s data plane—a significantly more complex and difficult attack path than a direct network connection.
Traffic Flow Analysis:
An administrator in the IT Zone (Level 4) connects via HTTPS to the Avi Controller Cluster VIP to configure a new WAF policy. This traffic remains entirely within Level 4.
The Avi Controller (Level 4) pushes the new policy configuration via a secure channel (TCP/8443) to the management interface of the SEs in the iDMZ Management Network (Level 3.5).
A user in the IT Zone (Level 4) opens a web browser and connects to an HMI application, resolving to a VIP on the iDMZ Front-End Network (Level 3.5).
The SE receives the connection, terminates the TLS session, and applies the WAF policy to inspect the HTTP request.
Assuming the request is legitimate, the SE uses its interface on the iDMZ Back-End Network (Level 3.5) to initiate a new, separate connection to the HMI web server in the Site Operations zone (Level 3).
The HMI server responds to the SE, which then relays the response back to the client. The client never communicates directly with the HMI server.
3.3 Data Flow Control and Policy Enforcement at the Boundary
By placing the AVI SEs in the iDMZ, they become the definitive Policy Enforcement Point (PEP) for all application-layer traffic crossing the IT/OT boundary, perfectly aligning with the Zero Trust model. This allows for the enforcement of granular security policies that go far beyond simple IP and port-based firewall rules.
The AVI platform can be configured to enforce the Purdue principle of unidirectional data flow where appropriate. For example, a Network Security Policy can be created that allows connections from a Level 4 business analytics server to a Level 3 data historian VIP, but denies any attempt by the historian to initiate connections back into the IT network. The most crucial function, however, is the termination and inspection of all traffic. By acting as a full proxy, the SEs break the network connection at the boundary, preventing attacks like malware propagation or network reconnaissance from passing directly from IT to OT.
Figure 3.1: Detailed Logical Architecture Diagram
Section 4: Implementing NIST 800-82 R3 Controls with VMware AVI
This section provides a practical mapping of specific security controls from the NIST SP 800-82 R3 OT overlay to concrete features and configurations within the VMware AVI platform. This demonstrates how the proposed architecture achieves a standards-based, verifiable security posture.
4.1 Enforcing Access Control (AC) at the IT/OT Boundary
The Access Control (AC) family of controls is fundamental to protecting the IT/OT boundary. AVI provides multiple layers of access enforcement for application traffic.
AC-3 (Access Enforcement) & AC-4 (Information Flow Enforcement): AVI enforces access and information flow policies at both Layer 4 and Layer 7. Network Security Policies function as Layer 4 access control lists (ACLs), allowing or denying traffic based on source/destination IP, port, and protocol. This can be used to restrict access to an OT application’s VIP to only authorized subnets within the IT network. More granularly, the Web Application Firewall (WAF) acts as a Layer 7 enforcement point, inspecting the content of the application traffic itself to block malicious payloads or unauthorized requests, thereby controlling the flow of information.
AC-17 (Remote Access): For web-based OT applications such as remote HMIs, the AVI platform can serve as a secure remote access gateway. By terminating the remote user’s connection at the SE in the iDMZ, AVI can enforce strong authentication policies, including integration with SAML or LDAP for multi-factor authentication, before allowing any traffic to proceed to the sensitive OT application server. All remote activity is logged and auditable through the platform.21
4.2 System and Communications Protection (SC)
The System and Communications Protection (SC) family focuses on securing the network infrastructure and the data transmitted across it.
SC-7 (Boundary Protection): The deployment of the AVI SEs within the iDMZ directly implements the core requirement of SC-7. The SEs act as managed interfaces at the boundary between the IT and OT zones, monitoring and controlling all communications that pass through them. This creates a chokepoint for inspection and policy enforcement, effectively isolating the OT network from untrusted IT traffic.
SC-8 (Transmission Confidentiality and Integrity): AVI provides robust capabilities for ensuring data in transit is protected. It can terminate TLS sessions from clients at the VIP, inspecting the decrypted traffic with the WAF. It can then re-encrypt the traffic before sending it to the back-end OT application server. This ensures that data is encrypted both on the IT side of the connection and on the OT side, creating a secure, end-to-end communication channel even if the back-end server has weak or outdated TLS capabilities.
SC-11 (Trusted Path): For critical user-to-application communications, such as an operator interacting with an HMI, AVI can help establish a trusted path. By using strong, validated SSL/TLS certificates on the virtual service, the platform provides assurance to the user’s browser that it is connecting to the legitimate, authenticated endpoint and not a spoofed or man-in-the-middle server.
4.3 Advanced WAF Protection for Critical OT Applications (e.g., HMIs, Historians)
OT applications, particularly web-based HMIs and data historian portals, are often high-value targets. They may be built on legacy code or custom platforms, making them susceptible to common web vulnerabilities. The AVI WAF provides a multi-faceted defense against these threats.
Applying OWASP CRS (Negative Security Model): The first layer of defense is the application of AVI’s default WAF policy, which is built upon the industry-standard OWASP ModSecurity Core Rule Set (CRS). This provides immediate, out-of-the-box protection against the OWASP Top 10 and other known attack signatures, such as SQL Injection (SQLi) and Cross-Site Scripting (XSS).
Implementing a Positive Security Model: The primary challenge in securing custom or legacy OT applications is that their specific vulnerabilities may not be covered by generic signature sets. A negative security model, which blocks known bad traffic, is insufficient against unknown or zero-day attacks. The AVI WAF addresses this through its machine learning-driven Positive Security Model.
Learning Mode: When a WAF policy is placed in “Learning Mode,” the AVI analytics engine observes legitimate traffic to the application. It automatically builds a profile of normal behavior, including valid URIs, parameters, request methods, and other attributes. From this profile, it generates a set of positive security rules that define what is allowed.
Tuning and False Positive Management: During the learning phase, the WAF may flag legitimate but unusual traffic as a potential false positive. The AVI UI provides explicit recommendations for these events, allowing an administrator to review the flagged transaction and, with a single click, accept a recommendation to create a specific rule exception. This streamlined workflow greatly simplifies the process of tuning the WAF policy to eliminate false positives without disabling broad categories of protection.
Phased Rollout Strategy (Detection vs. Enforcement): To prevent operational disruptions, WAF policies must be deployed in a phased manner. The policy should initially be applied to a virtual service in “Detection Mode.” In this mode, the WAF analyzes traffic and logs any rule violations but does not block any requests. After a period of monitoring and tuning to resolve any false positives, the policy can be confidently switched to “Enforcement Mode,” where it will actively block malicious traffic. This detect-then-enforce strategy is critical for gaining operational acceptance in risk-averse OT environments.
Table 4.1: NIST SP 800-82 R3 Control Mapping to VMware AVI Features
NIST Control Family & ID
NIST Control Objective
AVI Feature
Configuration/Implementation Notes
AC-3
Access Enforcement
Network Security Policy, WAF Policy
Create L4 ACLs to restrict VIP access to authorized source IPs. Apply L7 WAF rules to block unauthorized requests.
AC-4
Information Flow Enforcement
WAF Policy, L7 DataScripts
Use WAF to inspect and control application data flows. Use DataScripts for custom logic on complex flows.
AC-17
Remote Access
Virtual Service Authentication Profile
Configure virtual service to require SAML or LDAP authentication for users accessing web-based OT applications.
SC-7
Boundary Protection
Service Engine Deployment in iDMZ
Deploy SEs in the Level 3.5 iDMZ to act as the managed interface between the IT and OT networks.
SC-8
Transmission Confidentiality
SSL/TLS Profile, SSL Everywhere
Terminate and re-encrypt traffic at the SE. Apply an SSL Profile to the virtual service and the server pool.
SC-11
Trusted Path
SSL/TLS Profile with Trusted Certificates
Assign a valid, trusted certificate to the virtual service to provide authentication of the endpoint to the client.
SI-4
Information System Monitoring
WAF Policy, Anomaly Detection
Configure WAF in detection/enforcement mode. Monitor application health scores for security anomalies.
AU-2
Event Logging
Log Streaming to External Server
Configure SE Group to stream application and WAF logs in JSON format to a central SIEM for analysis and retention.
IR-4
Incident Handling
WAF Logs and Analytics
Use the detailed WAF logs and security insights dashboard to investigate alerts, identify attack vectors, and determine impact.
Section 5: Operationalizing Security: Advanced Monitoring, Logging, and Response
Deploying a secure architecture is only the first step; maintaining its security posture requires continuous monitoring, robust logging, and well-defined incident response procedures. The VMware AVI platform provides a rich set of integrated tools that move beyond simple log generation to offer deep, actionable insights into application health and security. This capability is particularly valuable in OT environments, which have historically suffered from a lack of visibility into application-layer traffic.
5.1 Continuous Monitoring with AVI Security Analytics
The AVI Controller provides a centralized dashboard for real-time monitoring of all managed applications, translating vast amounts of telemetry into easily digestible insights.
Application Health Scores: Each virtual service is assigned a Health Score from 0-100, which is a composite metric calculated from four components: Performance, Resource Penalty, Anomaly Penalty, and Security Penalty. A sudden drop in the Security Penalty score, for example, immediately alerts an operator to a potential issue, such as a DDoS attack or a spike in WAF-flagged transactions.
Security Insights Dashboard: For each virtual service, a dedicated Security dashboard provides a focused view of security-related events. This includes metrics on SSL/TLS transactions (e.g., failed handshakes, weak ciphers), DDoS attack details (e.g., attack type, mitigated traffic volume), and WAF analytics. This allows security personnel to quickly assess the security posture of an application without needing to sift through performance metrics.
Anomaly Detection: The platform’s analytics engine automatically establishes a baseline of normal behavior for each application across hundreds of metrics. It then uses machine learning to detect significant deviations from this baseline. These anomalies, such as a sudden spike in HTTP 500 error codes or an unusual increase in end-to-end latency, are flagged and can serve as early indicators of a security incident or an impending operational failure.
5.2 Centralized Logging for Forensic Analysis
While the Controller’s dashboards provide high-level insights, deep forensic analysis requires access to detailed transaction logs. AVI facilitates this by enabling the export of rich, structured logs to external Security Information and Event Management (SIEM) systems.
Configuring Secure Syslog Forwarding: The AVI platform can be configured to stream logs to an external syslog server. To ensure the confidentiality and integrity of this sensitive log data, the connection should be configured to use syslog over TLS. This requires configuring a PKI Profile on the Controller with the syslog server’s CA certificate and an SSL/TLS Profile with the Controller’s client certificate. The configuration is performed via the AVI CLI.
Leveraging JSON Log Formats: For maximum utility, logs should be exported in a structured format. AVI supports sending application and WAF logs in newline-delimited JSON (NDJSON) format. This format is easily parsable by modern SIEMs like Splunk and allows for powerful searching, correlation, and dashboarding based on specific fields within the log, such as client IP, requested URL, WAF rule ID, or response code.
Integrating with SIEM Platforms: To integrate with Splunk, a data input (e.g., TCP on port 9998) must be configured on a Splunk forwarder or indexer. A corresponding Splunk Add-on (e.g., Splunk Add-on for VMware ESXi Logs, which can be adapted) is then used to parse the incoming JSON data, extracting the fields and making them searchable within the Splunk platform. This integration transforms raw logs into a powerful forensic database.
5.3 Incident Investigation Workflow
The combination of real-time analytics on the AVI Controller and deep forensic data in the SIEM enables an efficient incident response workflow.
Alert Generation: An event, such as a WAF rule match in enforcement mode, triggers an alert. This alert is sent from the Avi Controller to the SIEM via the configured syslog-TLS forwarder.
Initial Triage in SIEM: The security analyst sees the alert in the SIEM console. The structured JSON log provides immediate context, such as the virtual service name, client IP address, and the specific WAF rule that was triggered (e.g., “SQL Injection Detected”).
Pivoting to AVI Analytics: For broader context, the analyst pivots to the AVI Controller UI and navigates to the Security dashboard for the affected virtual service. Here, they can see if this was an isolated event or part of a larger pattern, such as a distributed attack from multiple source IPs.
Deep-Dive Forensic Analysis: The analyst uses the virtual service’s “Logs” tab to perform a deep dive. They can filter for the specific transaction ID from the SIEM alert or filter by client IP. The log details provide the full, un-truncated request headers and body, showing the exact malicious payload that was blocked. This level of detail is critical for understanding the attacker’s methods and intent, and for providing definitive evidence for an incident report.
This integrated workflow bridges the often-problematic gap between real-time detection and deep forensic analysis. The AVI Controller’s analytics provide the immediate “what is happening now,” while the structured logs streamed to the SIEM provide the rich historical data needed to answer “what happened, how, and by whom.” This capability is often lacking in OT environments and represents a significant improvement in incident response readiness at the critical IT/OT boundary.
Section 6: Lifecycle Management for High-Availability OT Environments
In Operational Technology, system stability and availability are paramount. Any maintenance or upgrade activity must be meticulously planned and executed to minimize or, ideally, eliminate downtime. The architecture of the VMware AVI platform is designed with these stringent requirements in mind, offering robust procedures for backup, recovery, and zero-downtime upgrades that are essential for maintaining both the availability and the security posture of the application delivery infrastructure.
6.1 Controller Backup and Disaster Recovery
The Avi Controller cluster is the central point of configuration and management for the entire platform. A comprehensive backup and recovery strategy is therefore critical.
Backup Configuration: The AVI platform includes a native mechanism for automated, scheduled backups. This feature should be configured to export the full system configuration to a remote, secure server using SCP or SFTP. A strong, unique passphrase must be set to encrypt the backup file, ensuring the confidentiality of the configuration data. The schedule should be configured for daily backups, with a retention policy that aligns with the organization’s disaster recovery objectives.
Restore Procedure: In the event of a catastrophic failure of the entire Controller cluster, recovery is achieved through a well-defined procedure. The process involves deploying three new, factory-default Controller virtual machines with the same IP addresses as the original cluster members. Then, from the CLI of one of the new nodes, the restore_config.py script is executed. This script takes the encrypted backup file and the passphrase as input, restores the configuration, and automatically reforms the three-node cluster, including the cluster VIP. This scripted, predictable process ensures a reliable and efficient recovery of the entire management plane.
6.2 Zero-Downtime Upgrade Procedures
One of the most significant challenges in OT security is the reluctance to perform software updates due to the risk of downtime. This often leads to systems running with known vulnerabilities for extended periods. The AVI platform’s architecture directly addresses this challenge by enabling zero-downtime upgrades for the data plane.
Decoupled Plane Upgrades: The separation of the control and data planes allows them to be upgraded independently. The Controller cluster is upgraded first, followed by the Service Engine groups. This staged approach isolates the upgrade process and minimizes risk.
Controller Cluster Upgrade: The upgrade process is initiated from the Controller UI. All three nodes in the cluster are upgraded simultaneously. During this process, which typically takes several minutes, the management plane (UI and API) will be unavailable. However, the data plane is unaffected. All existing Service Engines will continue to operate on their current software version and forward application traffic without any interruption.
Service Engine Group Upgrade (Rolling Upgrade): This is the key to achieving zero data plane downtime. Once the Controller cluster upgrade is complete, the administrator can initiate the upgrade for each Service Engine Group. The Controller orchestrates a rolling upgrade process, handling one SE at a time. For a virtual service configured in an Elastic HA mode (N+M or Active/Active), the Controller’s workflow is as follows:
It places one SE in the group into a “maintenance mode.”
It gracefully migrates all virtual services from that SE to other available SEs within the same group.
Once the SE is no longer handling traffic, the Controller upgrades its software.
After the upgrade is complete and the SE is verified as healthy, it is brought back into service.
The process repeats for the next SE in the group until all SEs are running the new version.This automated, hitless process ensures that application traffic is never interrupted during the upgrade of the data plane components.
Upgrade Dry Run Feature: To further de-risk the upgrade process, AVI offers an “upgrade dry run” feature. This allows an administrator to test the upgrade in an isolated Docker container on a follower Controller node. The system performs a full upgrade of the configuration within the container and provides a detailed report of the outcome, all without impacting the live production environment. This provides a high degree of confidence that the actual upgrade will succeed.
The ability to perform zero-downtime upgrades of the data plane is a transformative capability for OT security. It directly resolves the long-standing conflict between maintaining availability and maintaining a strong security posture. By removing the operational barrier of required maintenance windows, this feature enables security teams to keep the critical enforcement points at the IT/OT boundary patched against the latest vulnerabilities, fundamentally improving the organization’s resilience to cyber threats.
Section 7: Conclusion and Strategic Recommendations
This blog has detailed a comprehensive architecture for deploying VMware AVI as a secure application delivery platform within an industrial network, grounded in the established principles of the Purdue Model and the prescriptive controls of NIST SP 800-82 Revision 3. By strategically placing the AVI Service Engines in the Industrial DMZ (Level 3.5) and the AVI Controller Cluster in the Enterprise Zone (Level 4), this design creates a robust, defensible, and highly observable boundary between the IT and OT environments.
7.1 Summary of Architectural Benefits
The integrated design presented herein offers a multitude of benefits that address the core challenges of modern OT security:
Standards-Based Security: The architecture is not based on ad-hoc decisions but is directly aligned with the Purdue Model for logical segmentation and implements specific, auditable controls from NIST SP 800-82 R3, ensuring a design that is rooted in industry best practices.
Zero Trust Enforcement: By functioning as a full proxy and Policy Enforcement Point in the iDMZ, the AVI platform enforces Zero Trust principles, ensuring that no traffic from the IT network is implicitly trusted and that all access to OT applications is explicitly authenticated, authorized, and inspected on a per-session basis.
Scalability and Resilience: The software-defined, scale-out architecture provides the elasticity to handle dynamic traffic loads, while the comprehensive High Availability models for both the control and data planes ensure the resilience required for mission-critical OT applications. The platform’s ability to self-heal by automatically migrating services from failed SEs further enhances operational continuity.
Deep Observability and Rapid Response: The platform’s integrated analytics engine, application health scores, and anomaly detection capabilities provide unprecedented real-time visibility into the security and performance of OT applications. When combined with the ability to stream rich, structured logs to a central SIEM, this creates a powerful ecosystem for proactive threat hunting and rapid forensic analysis, significantly reducing Mean Time To Resolution (MTTR) for security incidents.
Operational Viability in OT Environments: The architecture’s support for zero-downtime, rolling upgrades of the data plane directly addresses the primary operational constraint in OT environments—the intolerance for downtime. This allows security teams to maintain a strong patch posture without disrupting critical industrial processes, resolving the classic conflict between security and availability.
7.2 Implementation Roadmap
A phased implementation is recommended to ensure a smooth, low-risk adoption of this architecture.
Phase 1: Foundational Deployment and Passive Monitoring.
Actions: Deploy the 3-node Avi Controller cluster in the Level 4 IT zone. Create the necessary network segments for the iDMZ. Deploy an initial Service Engine Group in the iDMZ. Onboard a single, non-critical OT application (e.g., a development historian web portal). Apply a WAF policy in Detection Mode only. Configure log forwarding to the SIEM.
Goal: Establish the core platform and begin collecting baseline traffic data and security logs to gain visibility without any risk of production impact.
Phase 2: Policy Tuning and Initial Enforcement.
Actions: Analyze the logs and analytics from Phase 1. Use the WAF’s learning engine and log recommendations to tune the policy for the pilot application, creating exceptions for any identified false positives. Once confident, switch the WAF policy for the pilot application to Enforcement Mode.
Goal: Validate the security policy, the tuning workflow, and the incident response procedures on a non-critical application, ensuring all operational processes are sound.
Phase 3: Scaled Rollout.
Actions: Begin onboarding additional, more critical OT applications onto the platform. Repeat the “Detect -> Tune -> Enforce” cycle for each new application or group of similar applications. Scale out the Service Engine Group as needed to accommodate the increased load.
Goal: Systematically expand the security perimeter to protect all critical web-based applications at the IT/OT boundary.
Phase 4: Continuous Improvement.
Actions: Establish a regular operational rhythm for reviewing security dashboards, investigating anomalies, and tuning policies. Implement a schedule for performing zero-downtime upgrades of the AVI platform to ensure it remains patched against the latest vulnerabilities.
Goal: Transition from an implementation project to a mature, ongoing security operation focused on continuous monitoring and improvement.
By following this strategic roadmap, an organization can methodically and securely implement a modern, standards-based architecture that enables the benefits of IT/OT convergence while robustly defending its most critical assets.
Implementing a Defensible OT Architecture with VMware vDefend Distributed Firewall
The author wishes to acknowledge the valuable contributions and review provided by Joseph Polcar and Ken Hebenstreit, which greatly improved the quality and accuracy of this document.
An Architectural Guide for Aligning DFW with the Purdue Model and NIST SP 800-82 R3
Section 1: Introduction and Strategic Context
This document provides a comprehensive architectural design for leveraging the VMware vDefend Distributed Firewall (DFW) to implement the robust network segmentation required by the Purdue Enterprise Reference Architecture (PERA). This design is explicitly validated against the security controls and defense-in-depth principles mandated by NIST SP 800-82 Revision 3, “Guide to Operational Technology (OT) Security.”
This document focuses on the internal datacenter security fabric. The DFW’s unique, hypervisor-level enforcement capabilities make it the ideal platform for creating and enforcing the granular, Zero-Trust segmentation between the Enterprise Zone (Levels 4/5), the Industrial DMZ (Level 3.5), and the Site Operations Zone (Level 3).
The core objective of this design is to translate the logical zones of the Purdue Model into tangible, enforceable security policies within the NSX framework. This approach directly addresses key NIST 800-82 R3 tenets by establishing strong network boundaries, controlling information flow, and preventing unauthorized lateral movement, resulting in a defensible and standards-compliant industrial network environment.
Section 2: Core Concepts of the vDefend Distributed Firewall
The vDefend DFW is a software-defined firewall that is built directly into the hypervisor kernel. This architecture provides several fundamental advantages over traditional, appliance-based firewalls, making it uniquely suited to implementing NIST-recommended controls.
Ubiquitous Enforcement: Because the firewall is present on every host, it can enforce security policy on traffic between virtual machines on the same host and network segment. This provides true microsegmentation, a key principle of defense-in-depth, and eliminates the “hairpinning” of traffic to a physical firewall appliance.
Identity-Based Policy: DFW policies are not tied to static IP addresses. Instead, they are based on dynamic, identity-based constructs called NSX Security Groups. A group can be defined using a wide range of criteria, such as VM names, security tags, or OS versions. This allows for the creation of policies that are independent of network topology and that automatically adapt as workloads are created or moved, directly supporting the principle of least privilege (AC-6).
Centralized Management, Distributed Enforcement: All firewall policies are configured and managed from a single, centralized NSX Manager. The manager then pushes the relevant policies down to each individual hypervisor for enforcement. This model combines the simplicity of centralized management with the scalability and performance of distributed enforcement.
Section 3: Architecting PERA Zones with DFW Security Groups
The first step in implementing the design is to translate the logical levels of the Purdue Model into concrete NSX Security Groups. These groups will serve as the source and destination objects in our DFW rules.
A comprehensive tagging strategy is the foundation of this approach. Each virtual machine must be tagged with metadata that identifies its role and its place in the Purdue hierarchy.
Recommended Tagging Strategy:
Tag Scope
Tag Name
Example
PERA-Level
L4, L3.5-IDMZ, L3
A VM tagged with PERA-Level
Environment
Prod, Dev, Test
A VM tagged with Environment
Application
ERP, HMI-Portal, Historian
Identifies the specific application running on the VM.
Security Group Definitions:
Based on these tags, we will create the following high-level NSX Security Groups:
Group Name
Membership Criteria
Corresponding PERA Level
SG-PERA-L4-Enterprise
VM with Tag PERA-Level
L4
SG-PERA-L3.5-IDMZ
VM with Tag PERA-Level
L3.5-IDMZ
SG-PERA-L3-SiteOps
VM with Tag PERA-Level
L3
Section 4: DFW Policy Design for Enforcing Hierarchical Control
With the Security Groups defined, we can now construct the DFW policy to enforce the strict, hierarchical communication flows mandated by the Purdue Model. The policy will be organized into a dedicated DFW Section for clarity, with each rule explicitly mapped to its corresponding NIST 800-82 R3 control.
DFW Section: PERA Boundary Enforcement
Rule #
Name
Source
Destination
Service
Action
NIST 800-82 R3 Alignment
1
Process L4 Intra-Zone Traffic
SG-PERA-L4-Enterprise
SG-PERA-L4-Enterprise
Any
Jump to: L4 Application Segmentation
Delegates granular policy enforcement for internal L4 traffic.
2
Process IDMZ Intra-Zone Traffic
SG-PERA-L3.5-IDMZ
SG-PERA-L3.5-IDMZ
Any
Jump to: IDMZ Services Segmentation
Delegates granular policy enforcement for internal IDMZ traffic.
3
Process L3 Intra-Zone Traffic
SG-PERA-L3-SiteOps
SG-PERA-L3-SiteOps
Any
Jump to: L3 SiteOps Segmentation
Delegates granular policy enforcement for internal L3 traffic.
4
Allow IT to IDMZ
SG-PERA-L4-Enterprise
SG-PERA-L3.5-IDMZ
HTTPS, RDP, etc.
Allow
AC-4 (Information Flow Enforcement): Controls the flow of information between the IT zone and the IDMZ.
5
Allow IDMZ to OT
SG-PERA-L3.5-IDMZ
SG-PERA-L3-SiteOps
HTTPS, SQL, etc.
Allow
AC-4 (Information Flow Enforcement): Controls the flow of information between the IDMZ and the OT zone.
6
Block All Other Inter-Zone
Any
Any
Any
Drop
SC-7 (Boundary Protection): The critical “deny-all” rule that prevents all unauthorized lateral movement not explicitly allowed by the rules above.
This policy structure creates a digital “airlock.” A user in Level 4 can get to the “outer door” (the IDMZ), and the systems in the IDMZ can open the “inner door” (to the OT zone), but there is no way to open both doors at once. This directly implements the defense-in-depth and network segmentation principles of NIST 800-82 R3.
Section 5: DFW Health Checks and Operational Best Practices (NIST 800-82 R3)
Deploying the policy is only the first step. Maintaining its integrity and effectiveness requires ongoing operational discipline, directly aligning with the monitoring and maintenance controls of NIST 800-82 R3.
DFW Health Check & Rule Analysis:
Goal: Fulfill the need for a DFW health check, including identifying shadowed and redundant rules.
Implementation: Utilize vDefned Intelligence. this tool provides a powerful visualization of traffic flows and can automatically analyze the DFW rule base. They can identify:
Shadowed Rules: Rules that will never be hit because a broader rule above them in the policy already handles the traffic.
Redundant Rules: Duplicate rules that can be consolidated.
Unused Rules: Rules that have not seen any traffic over a specified period, which may be candidates for decommissioning.
NIST Alignment: This directly supports SI-4 (Information System Monitoring) by providing the tools to continuously monitor the effectiveness and efficiency of the security controls. It also supports RA-5 (Vulnerability Monitoring and Scanning) by identifying overly permissive rules that could create vulnerabilities.
Procedure and SOP Documentation Review:
Goal: Address the need for review and validation of operational procedures.
Recommendation: All operational procedures for managing the DFW must be documented. This includes:
Rule Request and Approval Workflow: A formal process for requesting a new firewall rule, including a justification, security review, and management approval.
Rule Implementation SOP: A standard operating procedure for implementing, testing, and validating a new rule.
Periodic Rule Review: A documented process for reviewing the entire DFW policy on a regular basis (e.g., quarterly) to decommission unnecessary rules and ensure the policy still aligns with business needs and the principle of least privilege.
NIST Alignment: This aligns with CM-3 (Configuration Change Control), PM-9 (Risk Management Strategy), and AC-2 (Account Management) by ensuring that access controls are reviewed and validated over time.
Gap Analysis and Recommendations:
Gap: Lack of a formal, automated process for tagging new VMs. This leads to new workloads not being placed in the correct security groups, rendering the DFW policy ineffective for those VMs.
Recommendation: Integrate NSX with an automation platform like vRealize Automation or Terraform. The deployment blueprint for any new VM should automatically apply the correct PERA-Level, Environment, and Application tags based on the request, ensuring that all workloads are protected by the DFW policy from the moment they are created.
NIST Alignment: This directly supports CM-2 (Baseline Configuration) by ensuring that all new systems are deployed with a secure, policy-compliant baseline configuration.
Section 6: Conclusion
By translating the logical zones of the Purdue Model into identity-based NSX Security Groups and enforcing communication policies with the vDefend Distributed Firewall, this design creates a powerful, scalable, and auditable security architecture. It moves beyond brittle, IP-based rules to a dynamic, software-defined model that is intrinsically and verifiably aligned with the core principles of Zero Trust and the specific control requirements of NIST SP 800-82 R3. This approach not only prevents unauthorized lateral movement but also provides the deep visibility and operational agility required to secure modern industrial environments in a standards-compliant manner.
Executive Summary: The Journey to a Unified Security Strategy
In today’s complex cybersecurity landscape, many organizations feel lost in a fog of compliance mandates and architectural shifts. The journey to a resilient security posture often seems like navigating a vast, unmapped territory. You’re handed multiple guidebooks: one detailing what controls you need (NIST 800-53), another describing where security is most critical (NIST 800-82 for OT), and a third explaining a radical new way of how to travel securely (NIST 800-207’s Zero Trust).
This blog charts a clear path through that fog. Let’s discuss how these are not separate, conflicting maps, but a single, cohesive guide for a unified security journey. By leveraging a modern platform like VMware’s vDefend, organizations can use the Zero Trust architecture as their vehicle to implement foundational controls across all their territories—from the corporate data center to the most critical industrial systems.
The Three Pillars of a Modern Security Strategy
Think of these three NIST publications as complementary pillars for a comprehensive security program:
NIST SP 800-53 (The “What”): This is the foundational catalog of what security and privacy controls need to be implemented. It provides a comprehensive, flexible framework for selecting and managing controls to protect organizational assets.
NIST SP 800-207 (The “How”): This document defines the modern architectural philosophy of how to implement security. Its Zero Trust Architecture (ZTA) mandates a shift from perimeter-based trust to a model of “never trust, always verify” for every access request.
NIST SP 800-82 (The “Where”): This standard focuses on where to apply these principles in a highly critical environment: Industrial Control Systems (ICS) and Operational Technology (OT). It provides specific guidance for securing the assets that control our physical world.
A successful strategy uses the architecture of 800-207 to implement the controls from 800-53 across both traditional IT and the specialized OT environments covered by 800-82.
VMware vDefend: The Unifying Platform
VMware vDefend is a suite of security solutions built directly into the virtual infrastructure, making it uniquely positioned to address these three pillars from a single point of control. Its key components—the Distributed Firewall, Advanced Threat Prevention (ATP) with Malware Prevention and NTA, Security Intelligence, and Network Detection and Response (NDR)—provide the technical mechanisms to turn policy into reality.
NIST 800-53 requires organizations to implement hundreds of technical controls. vDefend provides a direct path to satisfying many of them at scale.
Access Control (AC) & System and Communications Protection (SC): The vDefend Distributed Firewall is the core enforcement mechanism. By creating micro-segments around applications, it enforces the principle of least privilege (AC-3), controls the flow of information between security boundaries (AC-4, SC-7), and protects against denial-of-service attacks (SC-5).
System and Information Integrity (SI): The vDefend ATP suite is purpose-built for this. It provides malicious code protection (SI-3), monitors for unauthorized changes (SI-7), and uses its IDS/IPS and NTA engines to perform continuous system monitoring (SI-4).
Pillar 2: Adopting the Zero Trust Philosophy (NIST SP 800-207)
vDefend is not just a collection of tools; it is an architecture designed to operationalize Zero Trust.
Policy Enforcement: The Distributed Firewall acts as the perfect Policy Enforcement Point (PEP), as defined by NIST. It sits in the data path of every workload, enforcing access decisions on a per-session basis (Tenets 3 & 6).
Dynamic Policy: The NSX Manager acts as the Policy Engine (PE), using rich context from Security Intelligence and ATP to make dynamic, risk-based access decisions based on workload identity and security posture, not just static IP addresses (Tenets 4 & 5).
Telemetry and Visibility: The entire suite provides a constant stream of telemetry, from traffic flows to threat detections, allowing organizations to continuously monitor and improve their security posture, fulfilling a core requirement of Zero Trust (Tenet 7).
The principles of Zero Trust and the controls from NIST 800-53 are especially critical in OT environments. vDefend provides the tools to apply them effectively.
Electronic Security Perimeters (ESPs): NERC-CIP, a key framework related to 800-82, mandates the creation of ESPs. The vDefend Distributed Firewall is the ideal tool for this, creating a logical, software-defined micro-perimeter around any individual or group of BES Cyber Systems. This is far more granular and flexible than traditional, physical firewalls.
System Security Management: The firewall enforces a “default deny” policy, ensuring only explicitly approved ports and services are allowed (CIP-007). The ATP suite provides “virtual patching” via its IDS/IPS, protecting vulnerable OT systems that cannot be immediately patched.
Asset Identification:Security Intelligence provides the deep visibility needed to discover and map all OT assets and their communication flows, a critical first step for compliance (CIP-002).
Synthesized Approaches in Action
Scenario 1: The Utility Company vs. Ransomware
Consider a utility company that must comply with all three standards.
The Attack: An attacker sends a phishing email to an engineer, stealing credentials. They access a corporate workstation and begin internal reconnaissance, seeking a path to the SCADA control systems with the goal of deploying ransomware to disrupt operations.
Foundation (800-53): They use vDefend to implement baseline access controls (AC) and system integrity (SI) checks across their entire virtualized environment.
Philosophy (800-207): They adopt a Zero Trust model. Instead of just a perimeter firewall, they use the Distributed Firewall to create micro-segments around every application, both in their corporate IT and their SCADA control system environments.
Application (800-82): For their SCADA systems, they create an ultra-strict Electronic Security Perimeter using the firewall. The policy only allows traffic from specific operator consoles on designated ports. All other traffic is blocked and logged.
The Result & vDefend’s Intervention: The attacker’s reconnaissance scan is immediately flagged by the NTA engine as anomalous behavior. When they attempt to use the stolen credentials to connect to the SCADA environment, the Distributed Firewall (acting as a Zero Trust PEP) instantly blocks the connection because it originates from an unauthorized source, breaking the attack chain. If the attacker attempted to drop the ransomware payload, the Malware Prevention engine would detect and block it. The attack is stopped, compliance is maintained, and the grid remains secure.
Scenario 2: The Retail Giant vs. a Supply Chain Attack
Consider a retail giant with e-commerce platforms, physical stores, and automated distribution centers.
The Attack: A threat actor compromises a third-party software vendor and injects a malicious payload into a routine update for the Point-of-Sale (POS) terminals. The goal is to install a memory-scraper to steal credit card data and exfiltrate it.
Foundation (800-53): Their primary concern is protecting customer data (PII) and payment information. They use vDefend to implement strict access controls around their customer databases and payment processing systems, satisfying key AC and SI controls.
Philosophy (800-207): With thousands of stores and a massive cloud presence, the attack surface is huge. They adopt Zero Trust, using the Distributed Firewall to ensure a compromised POS terminal in one store cannot communicate with the central inventory system or another store’s network.
Application (800-82): Their automated distribution centers run on complex ICS/OT systems. They use the Distributed Firewall to create a secure zone around the warehouse management system, preventing a malware outbreak on the corporate network from halting their entire supply chain.
The Result & vDefend’s Intervention: The malicious update is deployed, but the Distributed Firewall’s micro-segmentation policy prevents the compromised POS terminal from communicating with anything other than its designated payment gateway. When the memory-scraper attempts to send stolen data to an external server, the NTA engine flags the anomalous outbound connection. The IDS/IPS may also detect the specific exploit technique. The breach is contained to a single terminal, preventing mass data theft and protecting supply chain operations.
Scenario 3: The Global Bank vs. a Zero-Day Exploit
Consider a global bank with complex legacy systems, modern cloud-native applications, and stringent regulatory requirements.
The Attack: An advanced attacker uses a zero-day exploit against a public-facing web application. Once inside, their goal is to pivot laterally to the internal SWIFT payment system to initiate fraudulent wire transfers.
Foundation (800-53): Data integrity and auditability are paramount. They use vDefend’s extensive logging and NDR capabilities to satisfy stringent Audit and Accountability (AU) controls, providing a complete record of every transaction flow for regulators.
Philosophy (800-207): The bank cannot trust any single component. They use a Zero Trust model to ensure that an application connecting to the SWIFT payment network has no access to the retail banking platform. Access is granted by the Policy Engine on a per-transaction, least-privilege basis.
Application (800-82): Their data centers are critical infrastructure. They use the Distributed Firewall to isolate the Building Management Systems (BMS) that control power and cooling, treating them as a critical OT environment. This prevents a cyberattack from causing a physical data center outage.
The Result & vDefend’s Intervention: The zero-day payload is analyzed by the Malware Prevention engine (sandboxing) and flagged as malicious. Even if the exploit succeeds, the Distributed Firewall’s Zero Trust policy makes the lateral pivot impossible—the compromised web server has no authorized path to the SWIFT system. The NDR console provides the security team with a complete visualization of the attack chain, from the initial exploit to the failed internal connection attempt, dramatically speeding up investigation and remediation.
Conclusion: Mastering the Terrain
The journey through the modern security landscape doesn’t have to be a disjointed scramble from one compliance checkpoint to the next. By understanding the roles of what to secure (800-53), how to secure it (800-207), and where it matters most (800-82), organizations can chart a clear, strategic course. A unified platform like VMware vDefend acts as the all-terrain vehicle for this journey, equipped to navigate the entire landscape. It provides the visibility to map the terrain, the granular control to stay on the path, and the threat intelligence to handle any obstacle. This unified approach transforms security from a reactive, compliance-driven exercise into a proactive strategy for building a truly resilient and defensible enterprise.